前言
其实早就写了,只是一直没发,工作太忙,没空呀~
上一篇链接——Acorn源码分析(1)
本篇将会分两次补全,现在是第一次~
nextToken():acorn中的词法分析
词法分析说起来比较简单,拆分代码字符串,分成一个个单词,并根据拆分出来的事件和状态得到结果。
token
token的意思我就不翻译了,这里介绍下token在acorn里的分类。在acorn里主要可以分为以下几种。
- kw:keyword 关键词
- name:普通名称
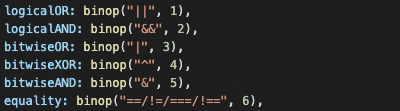
- binop:binary op 二进制运算符
- 符号类型
- eof:结束符
这里截个图展示下,大致就可以理解了。



acorn会将代码拆分成一个个单词,并根据type转化成一个个token,添加属性(位置,运算优先级等),方便用来词法分析。
词法状态机
说了token,就不得不说下词法状态机。毕竟代码的实现依赖于此。
acorn是写出来所有状态(token)再一步步走下去,这个是确定有限状态自动机.
acorn的词法状态机大概长这个样子。
 上面状态机中的大部分状态转换都会伴随着1个字符的消耗,但是有两种状态转换不消耗字符:
上面状态机中的大部分状态转换都会伴随着1个字符的消耗,但是有两种状态转换不消耗字符:
-
lookahead 表示“向前查看”,不消耗字符,比如:lookahead(1)意为向前查看1个字符,lookahead(0)表示查看当前字符。
-
is:keyword 表示匹配到的内容是某个关键字。
确定了状态机之后,看一下核心代码是怎么写的。
核心函数
从nextToken进去,核心部分主要是以下几个函数:
- nextToken
- readToken
- readWord
- getTokenFromCode
函数代码这里就不全放上来了,关于acorn源码的函数简化版本放在另一个文档,这里可以link过去。
首先说一下nextToken函数,这里挑一下重点说下。
nextToken = function() {
var curContext = this.context();
if(!curContetx || !curContext.preserveSpace) {
this.skipSpace();
}
// 获取当前位置为开始位置
this.start = this.pos;
if (this.options.locations) {
this.startLoc = this.curPosition();
}
// 结束位置
if (this.pos >= this.input.length) {
return this.finishToken(types.eof);
}
if (curContext.override) {
return curContext.override(this);
}
else {
this.readToken(this.fullCharCodeAtPos();
}
}
这是原汁原味的acorn源码,有些缩进、分号不规范的我改了,其他没区别。
nextToken方法主要负责更新token,里面主要是关注两段内容:
- finishToken:当所有字符都被消耗完毕时,调用finishToken将当前 token 变为eof
- readToken:如果没有要求对curContext覆盖重写的情况时,调用readToken(this.fullCharCodeAtPos())设置当前token
finishToken比较好理解,重点是readToken。
readToken
在说到readToken前,需要先说一下fullCharCodeAtPos这个函数,因为readToken接受的参数就是这个函数执行后的返回。
先上代码:
fullCharCodeAtPos = function() {
var code = this.input.charCodeAt(this.pos);
if (code <= 0xd7ff || code >= 0xe000) {
return code;
}
var next = this.input.charCodeAt(this.pos + 1);
return (code << 10) + next - 0x35fdc00;
}
看代码我们可以知道这里是将当前位置转成了**,然后进行了特殊的操作,最后返回位置信息的Unicode的码点。
至于为什么要这么做,原因是因为es5的年代,charCodeAt返回的事utf-16编码的,而有的字符超过了单个 utf-16 字符所能表示的范围,utf-16 使用两个字符来表示它,所以需要特殊处理。
当然,es6版本用codePointAt即可。
然后进入readToken,代码实现如下。
readToken = function() {
if (isIdentifierStart(code)) {
return this.readWord();
}
return this.getTokenFromCode(code);
}